DataBaker – making spreadsheets machine-readable
![]()
Spreadsheets are often the way of choice for publishing data. They look great, are understandable by people who don’t use databases, and with judicious use of formatting you can represent complicated datasets in a way people can understand.
The down side is that machines can’t understand them. Sure, you can export the file as CSV, but that doesn’t give you a nicely structured file with a single header row, as any other software needs to consume it.
This is a problem that we’ve encountered a few times. We started working on this problem for the United Nations Office for the Coordination of Humanitarian Affairs (OCHA), creating a library called XYPath to parse all sorts of spreadsheets using Python, as I’ve previously written about.
The Office for National Statistics currently publishes some of their data as spreadsheets, and they want that data in their new Data Explorer to make it far easier for people to analyse it. This is how the spreadsheets start out:
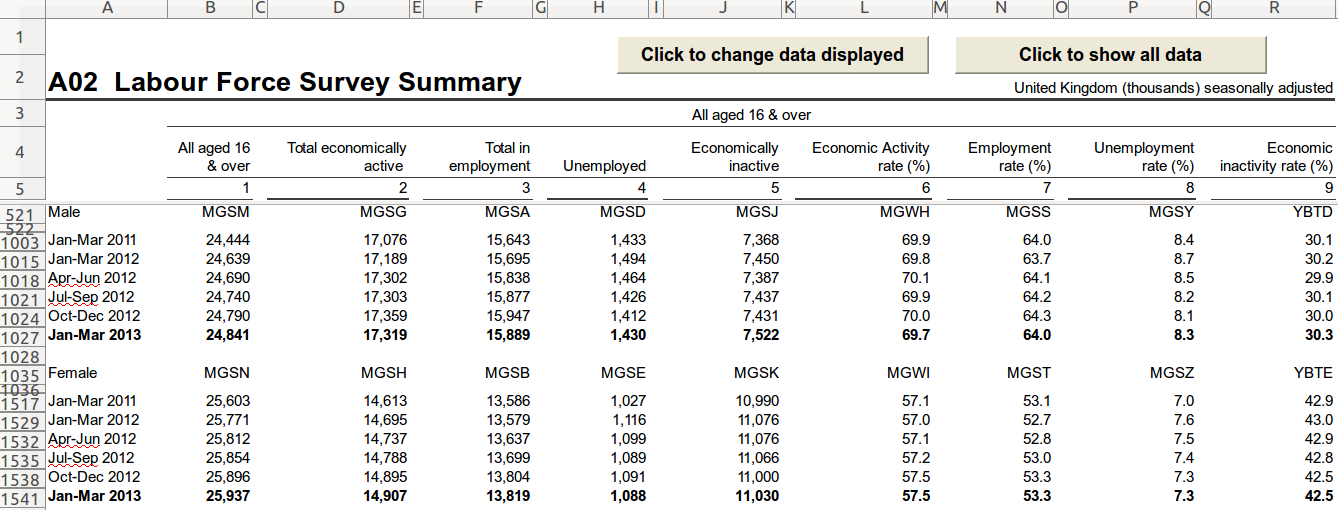
(Not shown: splits by age range, seasonal adjustments, most of the rest of the data or the whole pile of similar – but not quite similar enough – spreadsheets)
We’ve written databaker, which simplifies the entire process of converting spreadsheets like the one shown above to nicely structured CSV files. The recipe for this one is as follows:
- Use XYPath expressions to select the numbers you want, then select every set of headers (e.g. Male and Female; all the different dates).
- Add two words to describe where the headers are relative to the values: the dates are
DIRECTLY LEFTof the values, and we want theCLOSESTgender label which isABOVEthe value. - Finally, tell it which tabs to run on.
These ‘recipes’ are succinct for the simple cases, and the complicated cases are made possible, either through small snippets of Python or combinations of XYPath expressions.
It’s all Python, openly licensed, and available on GitHub.
And it’s always nice to have happy customers!
Who knew a little Python app spitting out CSVs could make people so happy but thank you team @ScraperWiki – great stuff 🙂
— Matt Jukes (@jukesie) February 20, 2015