Function reference
Core
bag.dimension(label, method, direction)
table.dimension(label, literal_value)
table.dimension(label, [subdimensions])
Use the first to specify a dimension to output, selecting the header cells so that the observations can find them in the first case, or a literal string value in the second. For more info, see the language page.
Subdimensions are exactly like dimensions, except:
- you use
.subdiminstead of.dimension - they don't have labels
- they don't appear independently in the output.
per_tab(tab)
Function run once per tab.
Must return the observations and set up any dimensions.
obs = tab.selector()
return obs
As per normal python, the return statement must be the last thing in the function.
per_file(tableset)
Must return either the names of the tabs, or individual items from tableset.
Consider using tableset.remove("unwanted tab") in the second instance.
You can get a list of tableset names with tableset.names
You can return them all with tableset or "*"
Constants
Directions
ABOVE (synonym for UP), BELOW (synonym for DOWN), LEFT, RIGHT
Special dimensions
- OBS is an observation, a particular piece of data.
- DATAMARKER refer to footnote-like things, for example
(a)to refer to approximate data. - GEOG is the GSS code, e.g.
E04001323. - TIME specifies the period, e.g. a year, month or quarter for which the
observation applies, e.g.
Feb-Apr 1971. - TIMEUNIT is the length of the time period, e.g.
Quarter. - Also STATPOP, UNITOFMEASURE, UNITMULTIPLIER, MEASURETYPE, STATUNIT.
Selection specifiers
How we get from observations to headers:
- CLOSEST (gets the first cell in the same column or row as the observation in a specified direction);
- DIRECTLY (gets the closest cell in the same column or row as the observation in a specified direction).
Bags
Set operators
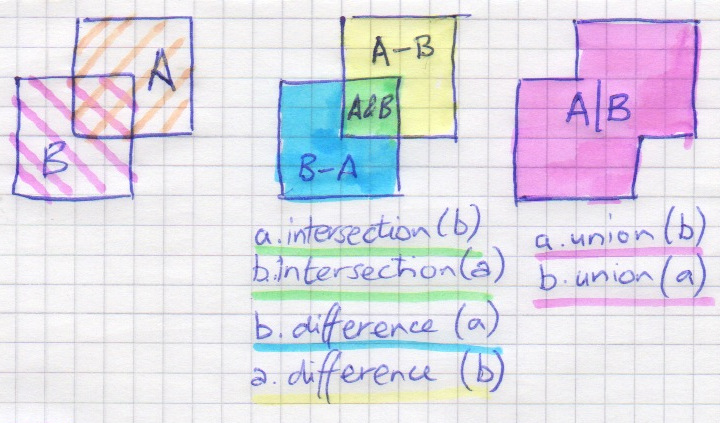
Bags are 'sets' of cells - and you can treat them just like Python sets.
Specifically, you can use:
newbag = bigbag | bag_of_cells_we_want # also .union
newbag = bigbag - bag_of_cells_we_dont # also .difference
newbag = bag & other_bag # also .intersection
bag.filter(string)
Return only the cells in the bag with a value of string. Typically there's only one, so this is often followed by .assert_one(). See later for other options to pass to select.
bag.one_of(list-of-selects) [db]
Return cells in the bag for which any of the selects match. selects are usually strings but could also be cell-functions (see the backend of bag.select, below)
bag.regex(regular-expression) [db]
Return cells whose values match the regular expression.
bag.assert_one()
Return the bag unchanged, so long as it contains exactly one cell. Otherwise crash.
bag.shift(x, y)
bag.shift(direction)
Return only cells which are exactly x cells to the right, and y cells down from a cell in the current bag. Either x or y can be negative to look left and up respectively.
There's no guarantee that you'll have the same number of cells afterwards; there might not be a cell at the new position.
You can also use any direction: UP, DOWN, LEFT, RIGHT, ABOVE, BELOW; or pass an (x,y) tuple.

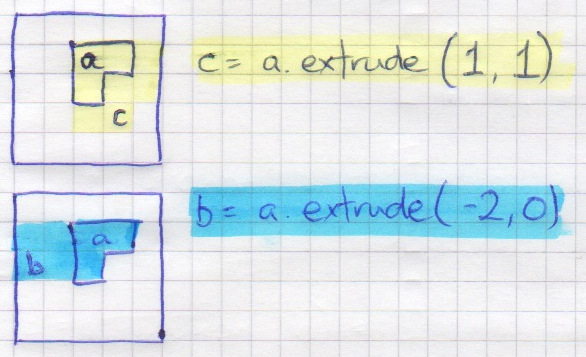
bag.extrude(x, y)
Get this cell, and all cells within x squares right of it, and y squares below it. x and y can be negative for left and up respectively.
bag.fill(direction)
bag.expand(direction)
From each of the cells in the bag, get all cells that are in the specified direction. fill doesn't include the original cells; expand does.
Note that this might get a lot of blank cells: consider using is_not_blank().
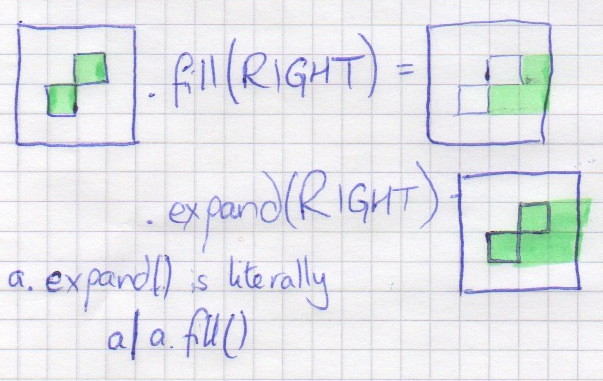
It also has a stop_before parameter: this takes a function which is tested against each bag; the fill/expand will stop if function(bag) is True. Note that this only works when cells are in a single row or column (specifically; the cells are scanned in book-reading order, left to right and top to bottom; we stop the first time the value is True)
bag.is_number() [DB]
Return only the cells in the bag which have a numeric value.
bag.is_date() [DB]
Return only the cells in the bag which are in one of the following string formats:
1999
1999 Q1
Jan 1999
Jan-Mar 1999
Note that currently this won't detect cells which are actually recognised by Excel as dates!
bag.spaceprefix(count)
Return cells which have count whitespace at the start, and then a non-whitespace character.
bag.is_XXX()
bag.is_not_XXX()
Return only the cells which are / are not a thing.
bag.is_not_bold()
bag.is_strikeout()
Options which make sense: bold, italic, strikeout, underline, blank, any_border, all_border, richtext, whitespace.
(is any border lined? are all four borders lined? is this cell richtext?)
bag.XXX_is(value)
bag.XXX_is_not(value)
Return only the cells for which the property has / doesn't have a particular value.
Options which make sense: size (in points), font_name (a string).
bag.font_name_is_not("Comic Sans MS")
bag.value
Returns the value of a single cell.
bag.parent()
For any spanned cells, get the top-left cell (which contains all the info).
Non-spanned cells are passed unchanged.
bag.children()
For any cell that is part of a span, get all cells that are parts of the span.
Useful for .fill(DOWN), but note that if the spanned cell is more than one row high, that'll include some of the spanned cells!
table.debug_dimensions() [db]
Adds debug dimensions - giving the table name and Excel cell reference - to the output CSV.
bag.group(regular-expression) [db]
For a single cell, get the matching group from the regular expression.
e.g. if the regular expression was -(.*)- and the cell's value was cat-dog-fish; this would return dog.
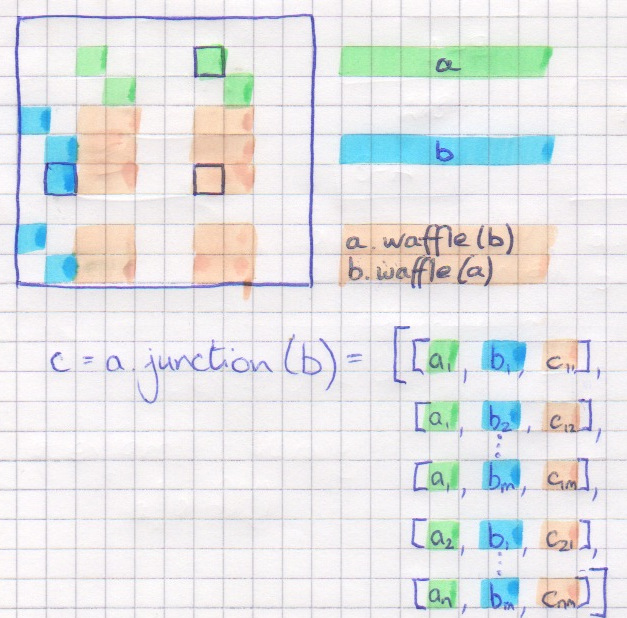
bag.waffle(other-bag)
Get all cells which have a cell from one bag above them, and the other bag to the side. Note that the two bags are interchangable without changing the output. You can change the direction from its default (DOWN) by specifying direction=LEFT or similar.
bag.same_row(other-bag)
bag.same_col(other-bag)
Get cells in this bag which are in the same row/column as a cell in the second.

bag.table
The table which these cells are from.
bag.by_index(index)
Get cells from this bag by their position in the bag: i.e. by_index(1) will get the first.
Can also pass lists of numbers: by_index([2,4,6,8]) but this might get removed in future,,
in favour of using standard Python indexes bag[4].
experimental : might remove and replace with standard pythonic indexes.
Table only
table.excel_ref(ref) [db]
Get cells from the table via an Excel cell reference: e.g. "G4", "C", "9", "Q5:Z9", "A:C", "9:88".
This is useful as a last resort if there's absolutely no other way of specifying a particular cell or cells. However, it's preferable to select cells via dimensions instead as these will be more robust to spreadsheet change.
For example, if all the cells are shifted right one in a new version of a spreadsheet, the desired cell will have shifted too, but the reference in the recipe won't be updated and the recipe will not behave as intended.
Shallow magic
These are reasonably detailed internals, but might be useful to know.
bag.select(function)
Get cells from the same table as these cells, based on a function.
The function must take two arguments: a bag cell, and a table cell.
If the function is True, the table cell will be in the output.
bag.select_other(lambda bag_cell, other_cell: foo, other_bag)
As bag.select except it inspects another bag rather than the bag's table.
This is useful because you can return cells from only a subset of the table, or use a different table entirely.
bag.junction(otherbag)
Similar to bag.waffle, except it outputs a list of the form
[
[bag_cell, otherbag_cell, cell_at_junction],
[bag_cell, otherbag_cell, cell_at_junction],
...
]
bag.select(cell-function)
This is the more general form of the 'filter' command.
Return only the cells in the bag for which the cell-function is true. These are typically written
python
bag.filter(lambda cell: cell.value > 20 and cell.y < 40)
or
def large_value_near_top(cell):
return cell.value > 20 and cell.y < 40
bag.filter(large_value_near_top)
Optionally, if you install hamcrest (pip install pyhamcrest) you can use their matching functions on the cell value - see the hamcrest documentation for the available functions.
bag.filter(hamcrest.equal_to("dog"))
Of specific interest is when the cell-function is re.compile(regular-expression): this is True when the regular expression matches the cell's value.
bag.glue(cell-function, join-function, blank=True)
WARNING : this function modifies cell values and has interesting side-effects. See details below.
Sometimes, what should be one cell in the output is split across multiple cells in the Excel spreadsheet. .glue rejoins these cells together.

The bag needs to contain the key cells: those which will contain values once we're done. For each of these cells, the cell_function is called on it, giving a range of ancillary cells which will provide their values to the key cell.
The key cell's value becomes the concatenation of it and the ancillary cells in reading order; the ancillary cells values are then wiped (unless blank is set to False)
This does not change the formatting properties of the cells: in particular, the cells are not spanned together.
The join_function defaults to concatenating the values together with space: a different function can be provided. (i.e. ' '.join)
It is strongly recommended that gluing of cells occurs as early as possible in the per_tab function: the results of other functions will change after a call to .glue.
Example code for above:
def per_tab(tab):
# ... code to acquire key_cells, e.g.
key_cells = tab.filter("All homes")
key_cells.glue(lambda cell: cell.extrude(0,3))
# all homes cells have been changed so the
# function we used gives us a different answer now
assert len(tab.filter("All homes")) == 0
# ... rest of per_tab function as per usual
tab.filter(re.compile("All homes.*")).dimension('location', DIRECTLY, ABOVE)
# ...
WARNING -- Unlike other functions this modifies the values of the cells. Inappropriate use can lead to inconsistent results! -- WARNING
Selectors which filter by the values of the affected cells -- like the ones used to select the key cells in the first place -- will return results based on the modified values after the use of .glue.
It is therefore strongly recommended that gluing of cells occurs as early as possible in the per_tab function.
Whilst .glue can be chained (it returns the bag of key cells provided to it; the bag is unchanged but the values of the cells in it are) it's not recommended since it isn't a 'pure' function.
Other things that might be useful, maybe.
scan.py looks for duplicated sets of dimension values
bag.pprint, .aslist and .excel_locations might be useful ways of displaying the data when debugging.